 OpsBird
OpsBird
AI Kubernetes Incident Response
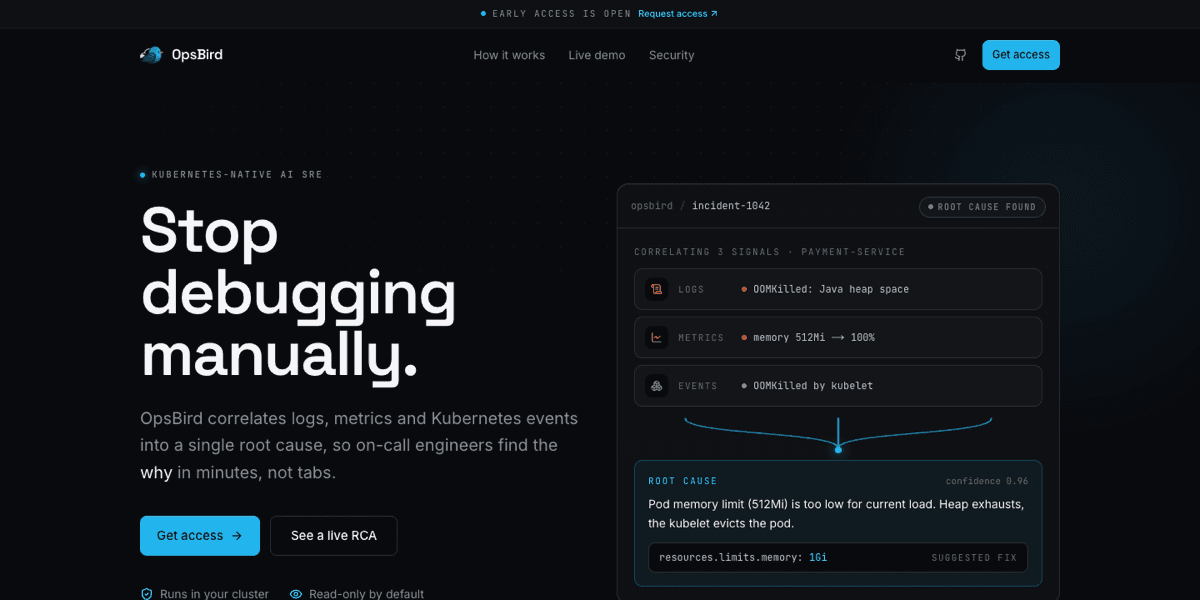
When a Kubernetes incident hits at 3 AM, engineers spend hours jumping between Grafana, kubectl, and log aggregators trying to piece together what happened. OpsBird eliminates that scramble. It's an AI-powered incident response platform that automatically correlates logs, metrics, and Kubernetes events to pinpoint root causes with high confidence - in seconds. From CrashLoopBackOff to OOMKilled to latency spikes, OpsBird analyzes millions of signals and delivers a single, actionable explanation. Enterprise-ready, with on-premise deployment for teams that need their data to stay in their VPC.
Highlights
How it Works
Connect Your Cluster
Install the OpsBird agent via Helm chart. It starts collecting Kubernetes events, logs, and metrics from your cluster.
Detect Incidents
OpsBird continuously monitors your cluster and automatically identifies anomalies, failures, and performance degradations.
Correlate Signals
AI analyzes millions of data points across logs, metrics, and K8s events to find the connections humans would miss.
Deliver Root Cause
Get a clear explanation of what broke, why, and what to do about it - delivered to Slack, Teams, or the OpsBird dashboard.
Features
AI Triage & Correlation
Analyzes millions of signals from Kubernetes events, logs, and metrics to group related alerts into a single, actionable incident. Turns alert noise into clarity.
Instant Root Cause Analysis
Automatically links crash loops to recent image tag updates, configmap changes, or resource limits. Delivers root cause with confidence scores in seconds.
Kubernetes-Native Intelligence
Deep semantic understanding of Pods, Services, Nodes, and cluster topology. OpsBird speaks the language of your infrastructure - not just pattern-matching on log lines.
Slack & Teams Integration
Delivers root cause analysis directly to your incident channels. Engineers get actionable context without leaving their communication tool.
Interactive Incident Demos
Explore how OpsBird handles CrashLoopBackOff, OOMKilled, and latency spike scenarios through interactive walkthroughs before connecting your own cluster.
On-Premise Deployment
Self-hosted option ensures your telemetry data never leaves your infrastructure. Full feature parity with the cloud version, deployed inside your VPC.
Use Cases
CrashLoopBackOff Diagnosis
Instantly correlate pod crashes with recent deployments, config changes, or resource exhaustion - no more guessing which commit broke it.
OOMKilled Resolution
Trace memory limit violations back to specific workloads and get recommended resource adjustments based on historical usage patterns.
Latency Spike Investigation
Correlate API response time spikes with database lock contention, missing indexes, or upstream dependency failures across your service mesh.
On-Call Acceleration
Reduce MTTR from hours to minutes. On-call engineers get root cause context immediately instead of manually correlating dashboards at 3 AM.
Who it's For
SREs, DevOps engineers, platform teams, and on-call engineers running production Kubernetes clusters who need to reduce mean time to resolution.
Ready to try OpsBird? See it in action.
Visit OpsBirdFAQ
OpsBird is an AI-powered incident response platform for Kubernetes. It automatically correlates logs, metrics, and Kubernetes events to pinpoint the root cause of an incident with high confidence, in seconds.
Not with the self-hosted option. OpsBird offers on-premise deployment with full feature parity, deployed inside your VPC, so your telemetry data never leaves your infrastructure.
It handles scenarios like CrashLoopBackOff, OOMKilled, and latency spikes, linking crashes to recent image tag updates, configmap changes, or resource limits.
You install the OpsBird agent via a Helm chart. It then collects Kubernetes events, logs, and metrics and continuously monitors the cluster for anomalies and failures.
Root cause analysis is delivered directly to your incident channels through Slack and Teams integration, as well as the OpsBird dashboard.
Want something like OpsBird?
KUBERSTAR designed and built OpsBird. Tell us what you have in mind and the same team can build it for you.
More to Explore
 AriSend
AriSend
AI sales rep that handles Facebook, Instagram, WhatsApp, and Telegram chats 24/7 - qualifying leads, booking appointments, and closing sales while you sleep.
 AskFormulas
AskFormulas
Instant formula reference for math, physics, chemistry, and engineering. Search equations, convert units, and browse organized formula collections.
 TUGANQ
TUGANQ
Multilingual Armenian legal reference portal - traffic fines, state duties, legal procedures, and law articles in Armenian, Russian, and English.